如何在pandas中使用set |
您所在的位置:网站首页 › pandas 设置列名称 › 如何在pandas中使用set |
如何在pandas中使用set
| 在数据分析过程中,有时出于增强数据可读性或其他原因,我们需要对数据表的索引值进行设定。在之前的文章中也有涉及过,在我们的pandas中,常用set_index( )与reset_index( )这两个函数进行索引设置,下面我们来了解一下这两个函数的用法。一、set_index( ) 1、函数体及主要参数解释: DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)参数解释: keys:列标签或列标签/数组列表,需要设置为索引的列 drop:默认为True,删除用作新索引的列 append:是否将列附加到现有索引,默认为False。 inplace:输入布尔值,表示当前操作是否对原数据生效,默认为False。 verify_integrity:检查新索引的副本。否则,请将检查推迟到必要时进行。将其设置为false将提高该方法的性能,默认为false。 2、实例说明: 首先还是先创建一个实验数据表: import pandas as pd import numpy as np df = pd.DataFrame({'Country':['China','China', 'India', 'India', 'America', 'Japan', 'China', 'India'], 'Income':[10000, 10000, 5000, 5002, 40000, 50000, 8000, 5000], 'Age':[50, 43, 34, 40, 25, 25, 45, 32]}) df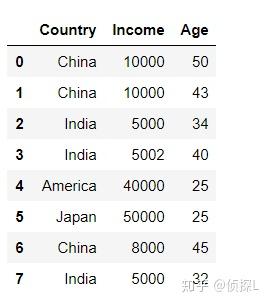 下面我们尝试将‘Country’这一列作为索引: df_new = df.set_index('Country',drop=True, append=False, inplace=False, verify_integrity=False) df_new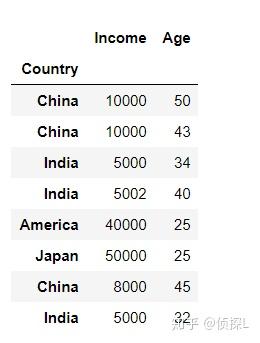 可以看到,在上一步的代码中,是指定了drop=True,也就是删除用作新索引的列,下面师门尝试将drop=False. df_new1 = df.set_index('Country',drop=False, append=False, inplace=False, verify_integrity=False) df_new1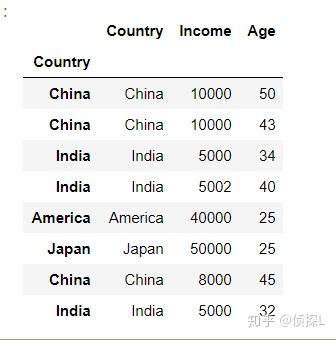 可以看到这个时候,被作为索引的那一列数据仍然被保留下来了。 下面,我们再探索一下append参数的用法。(append的用法:是否将列附加到现有索引,默认为False。) 由上面代码结果可以看到,当append=False时: 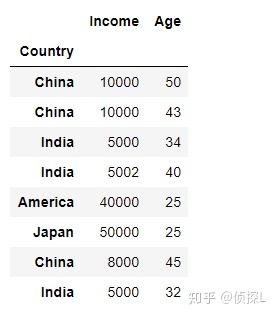 我们来试试append=True的情况: df_new1 = df.set_index('Country',drop=True, append=True, inplace=False, verify_integrity=False) df_new1 可以看到,原来的索引和新索引一起被保留下来了。 二、reset_index( )1、函数体及主要参数解释: DataFrame.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill='')参数解释: level:数值类型可以为:int、str、tuple或list,默认无,仅从索引中删除给定级别。默认情况下移除所有级别。控制了具体要还原的那个等级的索引 。 drop:当指定drop=False时,则索引列会被还原为普通列;否则,经设置后的新索引值被会丢弃。默认为False。 inplace:输入布尔值,表示当前操作是否对原数据生效,默认为False。 col_level:数值类型为int或str,默认值为0,如果列有多个级别,则确定将标签插入到哪个级别。默认情况下,它将插入到第一级。 col_fill:对象,默认‘’,如果列有多个级别,则确定其他级别的命名方式。如果没有,则重复索引名。 注意~~~reset_index()还原可分为两种类型,第一种是对原来的数据表进行reset;第二种是对使用过set_index()函数的数据表进行reset。2、实例说明 (1)我们先看一下第二种情况,即对使用过set_index()函数的数据表进行reset: 还是一样,看下原来的数据表:  然后使用set_index()函数进行索引设置: df_new = df.set_index('Country',drop=True, append=False, inplace=False, verify_integrity=False) df_new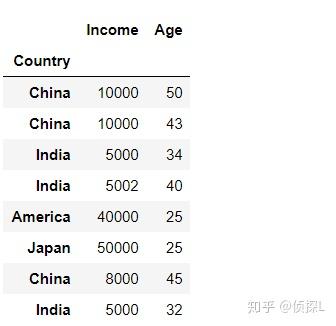 下面,用reset_index()函数进行还原:(看清楚哦,这个时候我们指定drop=False) df_new01 = df_new.reset_index(drop=False) df_new01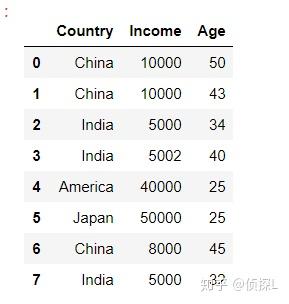 可以看到,被作为索引的列被还原成原来的样子。 我们再来看看当drop=True时的情况: df_new02 = df_new.reset_index(drop=True) df_new02 可以看到,刚刚经过处理后的新索引被删除了。 (2)再看下第一种情况,即对原来的数据表进行reset处理: 还是先来看看原来的数据表:  接着,我们直接对这个数据表使用reset_index()函数(还是一样先指定drop=False): df_new03 = df.reset_index(drop=False) df_new03 可以看到,此时数据表在原有的索引不变的基础上,添加了列名为index的新列,同时在新列上进行重置索引。 下面,我们再指定drop=True: df_new04 = df.reset_index(drop=True) df_new04 可以看到,输出结果和原来的数据表没有区别。但是其实在这个时候是有操作的,是在原有的索引列重置索引,同时不另外添加新列。这个常用于索引的重置,在进行数据删减处理的时候能派上很大的用场哦~详情请看: 由于在reset_index()函数中比较多用法drop参数,其他参数用的比较少,因此在这里我们就只演示drop的用法,感兴趣的同学可以自己动手试试~ 以上便是的内容,感谢大家的细心阅读,同时欢迎感兴趣的小伙伴一起讨论、学习,想要了解更多内容的可以看我的其他文章,同时可以持续关注我的动态~ |
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |